

This blog post was originally presented at the FHIR North 2023 conference. You can rewatch the original presentation here.
One of the biggest challenges remaining in healthcare is cumbersome and lengthy system integrations and the interoperability between those systems. In fact, most hospitals in Canada still use HL7v2 for integration capabilities for various business-critical systems such as the ADT (Admission, Discharge, Transfer) feeds and appointment scheduling feeds.
A brief introduction on HL7v2
Health Level Seven created HL7v2 1989 as a communication standard. Below is an illustration of what a typical message from one of our appointment scheduling solutions might look like if it was sent over HL7v2:

As you can see above, HL7v2 messages are text-based messages that are separated by pipes and carets. Each line in a message represents specific information. For example, the PID line represents Patient Demographics Information, whereas the PV1 line represents a patient visit.
The standard was built mainly to be decoded by computers and not read by humans. HL7 FHIR, on the other hand, was designed to be human-readable in JSON format.

Although HL7v2 was not explicitly written to be human-readable, it’s still possible for us to extract the information necessary to understand the messages. To do this, however, we first need to understand the specifications of the standard. At that point, it may seem more straightforward to translate HL7v2 messages to more structured HL7 FHIR messages, but we can still run into problems with interoperability.
Existing solutions to translate HL7v2 to HL7 FHIR
Large corporations have already created various parsers that aim to translate HL7v2 to HL7 FHIR. You can find two such examples below:
As you’ll discover later in this post, these converters often lack even simple integration capabilities because they only offer “syntactic interoperability.” Essentially, this means that each field is understood at face value and nothing more.
Real Problem #1: Many implementations store additional details in custom segments

Above are three lines from the HL7v2 message in the previous example image. If someone were to pass this through a conventional converter, it might be translated into a FHIR DocumentReference object…if you’re lucky. However, A human who understands the specifications of HL7v2 may be able to discern a couple of things from this message.
First off, NTE stands for Notes and Comments. Next, we can see that two of these lines relate to contact methods. What isn’t explicit is the fact that these lines represent consent. The patient has given consent to be contacted by phone but declined to be contacted by email.
The issue is that HL7v2 doesn’t support consent workflows, so implementers will add custom segments, like using notes and comments to store consent values. These customizations can lead to complications, as you’ll find out below.
Real problem #2: Workflows vary across implementations

At Verto, we’ve worked with many HL7v2 implementations. We’ve found that a particular HL7v2 message type may not contain the same information even within the same hospital network. It’s dependent on how each organization within the network adopted the standard and which customizations have been used.
See the image above to illustrate our point. Here, “Hospital A” uses value S12 as the “Visit Type” field. Let’s say for “Diabetes Followup,” for example.
“Hospital B,” however, uses S12 for different information altogether. In our example, Hospital B uses S12 for “Pre-admission” messages in their ADT (Admission, Discharge, Transfer) system. Hospital B is instead using value A05 as their “Vist Type” field, which isn’t compatible.
Current Solution: Hire Business Analysts
The current solution is hiring business analysts to discover and understand hospitals' high-level workflows. Those analysts also have to perform a deep dive into each message and manually create mappings (recall that we cannot use existing converters out of the box). This method is clearly both labor-intensive and highly time-consuming.
At Verto, we’re always working towards faster integration times. The sooner we complete integrations, the sooner our clients are onboarded to benefit from Verto’s Digital Twin technology.
The Verto AI Solution
However, we’re not stuck with these HL7v2 integration problems. Verto has invented and patented a solution: "Method and system for consolidating heterogeneous electronic health data."
The first step is to listen to one or more HL7v2 feeds passively. Next, we analyze it with our defined "Four Pillars": Positional Encoding, Data Type, Temporal and Adjacency. Below are explanations of each Pillar.
Positional Encoding
Positional Encoding performs syntactic analysis with existing HL7v2 specifications. We are not reinventing the wheel here. The method of this pillar can be as simple as running the message through an existing HL7v2 translator to obtain what the field is supposed to mean at face value. This method works very well for some segments, for example, Patient Demographics.
However, it is easy to see through the above example that positional encodings can only get us so far. We'll need to understand much more.
Data Type
This pillar attempts to verify whether or not the positional encoding holds up independently. It is achieved through performing feature engineering on independent fields, such as:
- Alphabetical
- Alphanumeric
- Custom regexes
- Dictionary matching
- Common NER categories
For example, with the methods in this pillar, we can train a model to detect an Ontario health card based solely on its attributes (whether or not a value is alphanumeric, if the number contains a check digit, etc.)

Another possibility is that the value matches a dictionary element that we support, such as ICD-10 clinical concepts (e.g., I10 - Essential Primary Hypertension) or even a last name. Since we are analyzing it for hundreds of thousands of messages, it is sufficient to come to a conclusion even if only 70% of the values match the "Last Name dictionary".
Temporal
This layer aims to infer data type independently by performing temporal comparisons with other values in the same position. Again, since we are examining a group of messages, we can analyze many values belonging to a single field.
For example, we might detect that this field is integer-incremental in nature (i.e. values that count up by 1). These values are often identifiers, such as patient and appointment identifiers.
Another example would be boolean values. If we have detected only two values, it likely represents True or False. What's more likely is detecting three values, where one value is NULL.
Equally likely is analysis on empty values (null values). The percentage of null values might indicate how valuable mapping would be.
Adjacency
This layer aims to infer a data type based on adjacent elements. This pillar is one of the most important due to how HL7v2 messages are formatted. In this example, by observing the N-1 and the N+1 word, we can conclude that multiple patient identifiers are involved (i.e., the unique patient identifier and the Medical Record Number).
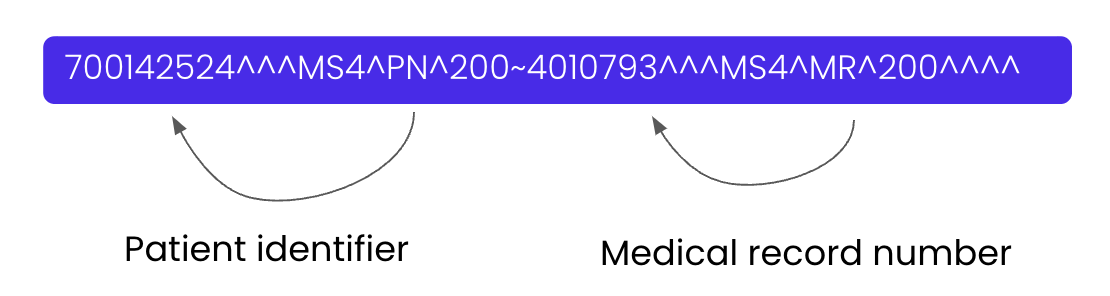
Our Consent Mappings
With the above pillars understood, let's go back to our original problem and see how these pillars performed in this situation:
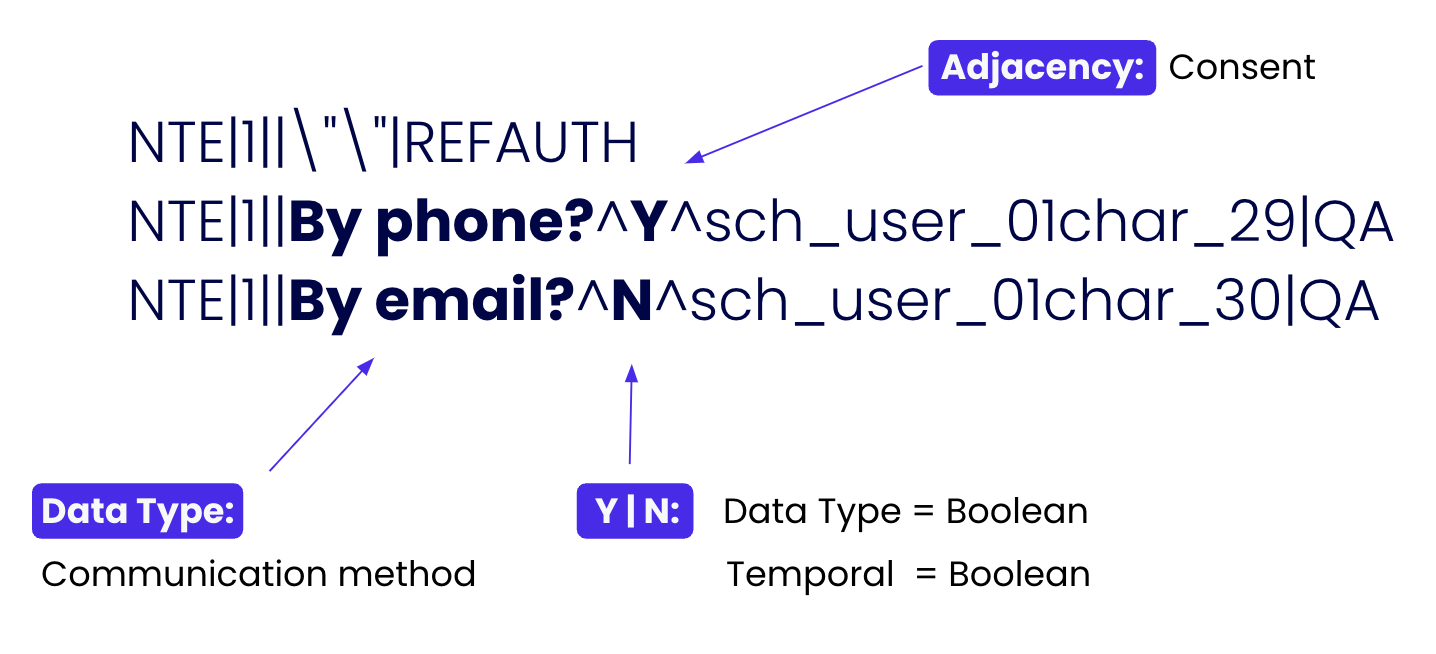
Through analysis, we can recognize that the "Notes and Comments" section (NTE) stores patient consent. With this automated mapping, we can now perform orchestration more confidently. That is, we can send emails and text messages with assurance that they comply with the “Patient Consent” values!
Manual Review of Mappings
However, humans should not be kept out of the loop in any responsible use of AI. As with any AI process, Verto allows humans to review generated mappings and confirm or reject mappings. For each field mapped, justifications will be outputted for each Pillar that made it, like how the consent segment was deconstructed above.
The Payoff
What we've done here has exponentially decreased integration time. The result speaks for itself: we can obtain OLIS (Ontario Lab Information System) certification in only four weeks, whereas the typical integration timeline is eight months!
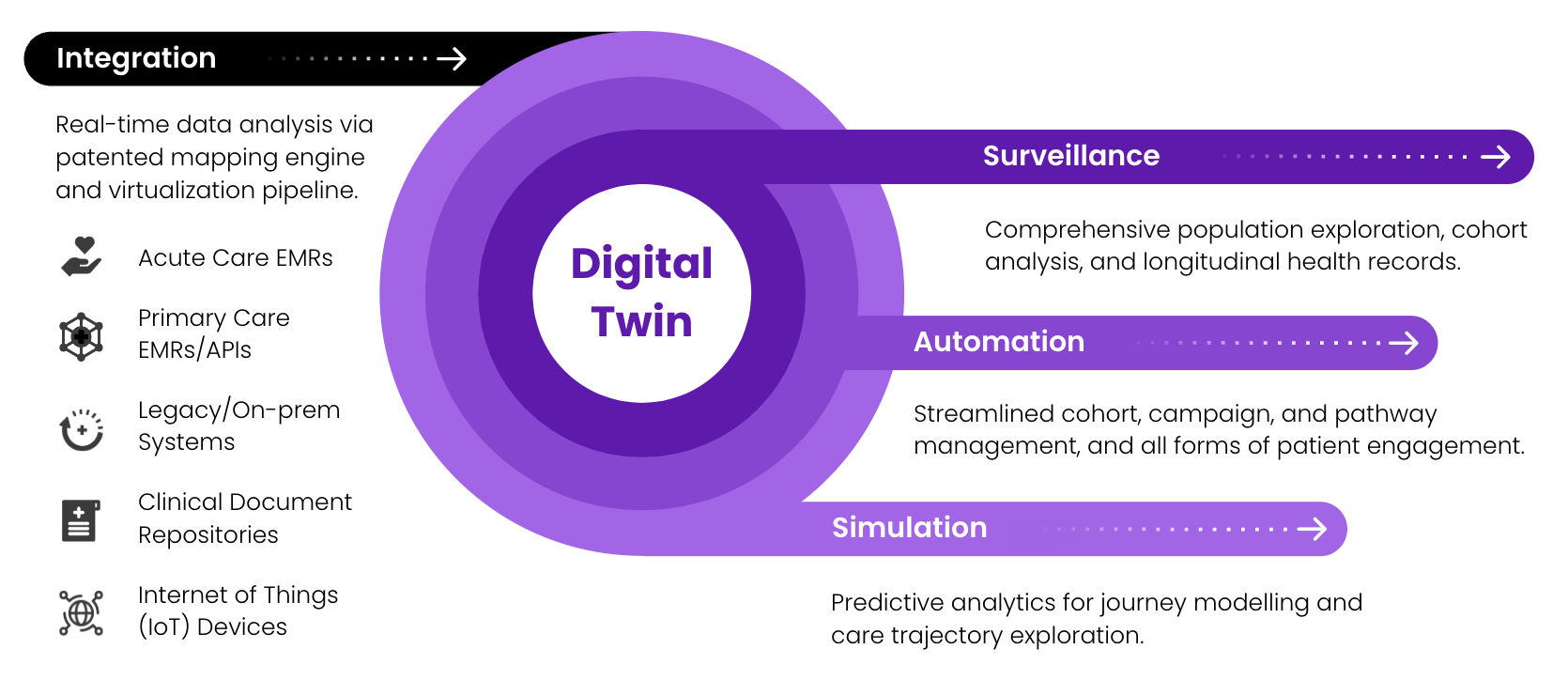
The outcome is that Verto can now translate HL7v2 messages to HL7 FHIR without any loss of information. For example, we can use these messages in our Digital Twin technology to perform comprehensive population exploration. Then, we can use the results to trigger powerful automation processes (like improved and focused alerting for clinicians and patient segments). The possibilities are exciting!
If you find what we're doing here interesting, we are always looking for like-minded individuals to join our team! Feel free to take a look at open positions here and we'll talk!